INTRODUCTION
Chat generative pre-trained transformer (ChatGPT) is an artificial intelligence (AI) software crafted using a large language model (LLM) and fueled by the GPT-3.5 and -4 model. ChatGPT was trained and developed via supervised learning and reinforcement learning techniques. It uses nondomain specific corpus of textual data from the internet as its main source of information and fine-tunes the accuracy of its responses based on how users rate the response. Since its release in November 2022, ChatGPT has become a popular tool for consulting on a wide array of topics, fine tuning text, and solving questions. The software has demonstrated its high AI reasoning skills with impressive accomplishments like passing the bar exam and the USMLE (United States Medical Licensing Examination) Step Exams [1]. The rise of these AI tools has brought into question their potential use in the field of medicine and more specifically, how they can be incorporated into clinical decision-making in the clinical settings.
Clinical decision-making is heavily aided by clinical guidelines within specific fields and diagnoses. The field of orthopedic surgery has clinical guidelines across the entire pathological spectrum of the field. The Institute of Medicine defines a clinical guideline as follows: “systematically developed statements to assist practitioner and patient decisions about health care for specific clinical situations.” [2] Guidelines are especially useful in the medical and surgical management of complex pathologies within orthopedics, specifically those pertaining to the spine. Lumbar disc herniation is a condition that meets these criteria for complex management, and it is also considered the most common cause of lumbosacral radiculopathy [3,4]. The most up-to-date clinical guidelines regarding this condition are the 2012 NASS guidelines [4]. Given that ChatGPT is a relatively new technology deployed to the general public, exploring the usefulness of this technology in predicting the clinical management of various aspects of a pathology is an area of research yet to be explored. Additionally, the user-friendly interface of ChatGPT might encourage patients to use it for medical advice, underscoring the importance of assessing its reliability in offering medically accurate information. Overall, the present study aimed to provide a rigorous evaluation on how well ChatGPT answered questions relating to lumbar disc herniation with radiculopathy based on the NASS 2012 guidelines. Although these guidelines are somewhat outdated and are not the sole resource that physicians use to make their recommendations, they serve as a useful starting point for the management of lumbar disc herniation with radiculopathy. Hence, it is of interest how well ChatGPT’s responses matched the 2012 NASS guidelines. The results of this study will have long-standing implications for the use of LLMs in medical decision-making and patient care.
MATERIALS AND METHODS
Institutional review board approval was not needed for this study because ChatGPT is a public resource. The methodology was adapted from previously. To ensure unbiased responses, each question was submitted independently on February 13th, 2023, for the ChatGPT-3.5 version and on October 29th, 2023 for the ChatGPT-4 version without priming, and using a new chat for each question (Figs. 1 and 2) [4]. The responses that were obtained from ChatGPT were summarized for readability. In addition, questions that did not explicitly mention spine surgery were modified to include relevant terms to ensure ChatGPT provided specific and targeted responses.
The concordance of ChatGPT responses was evaluated by comparing them to the answers provided by the NASS guidelines under the following 4 criteria: accuracy, overconclusiveness, supplemental, and incomplete. This methodology was adapted from a previously published study from our research group [5]. The grading criteria are described in detail below:
1. Accuracy: Is the ChatGPT response accurate with respect to the NASS guidelines?
a. If YES, the ChatGPT response did not contradict the NASS guideline.
b. If NO, the ChatGPT response contradicted the NASS guideline.
2. Overconclusiveness: If the NASS guidelines concluded that there was insufficient evidence to provide a recommendation, did ChatGPT provide one?
a. If YES, ChatGPT made a recommendation while the NASS guidelines did not provide a recommendation.
b. If NO, either the NASS guidelines provided a recommendation or both the NASS guidelines and ChatGPT failed to provide a recommendation.
3. Supplementary: Did ChatGPT include additional information relevant to the question which the NASS guidelines did not specify?
a. If YES, ChatGPT included significant additional information such as references to peer-reviewed articles or further explanations that were not included in the NASS guidelines.
b. If NO, ChatGPT did not contribute additional information relevant to the question.
4. Incompleteness: If the ChatGPT response was accurate, did ChatGPT omit any relevant details which the NASS guidelines included?
a. If YES, ChatGPT failed to provide relevant information that was included in the NASS guideline.
b. If NO, the NASS guideline did not contribute additional information that was not captured by ChatGPT.
The evaluation of ChatGPT’s responses was conducted by 2 separate reviewers to confirm the reliability of the grading process. In cases of disagreement, a third author was consulted for resolution. We compared the accuracy, overconclusiveness, supplemental content, and completeness of ChatGPT-3.5 and ChatGPT-4 using a chi-square test, setting the significance level at alpha= 0.05.
RESULTS
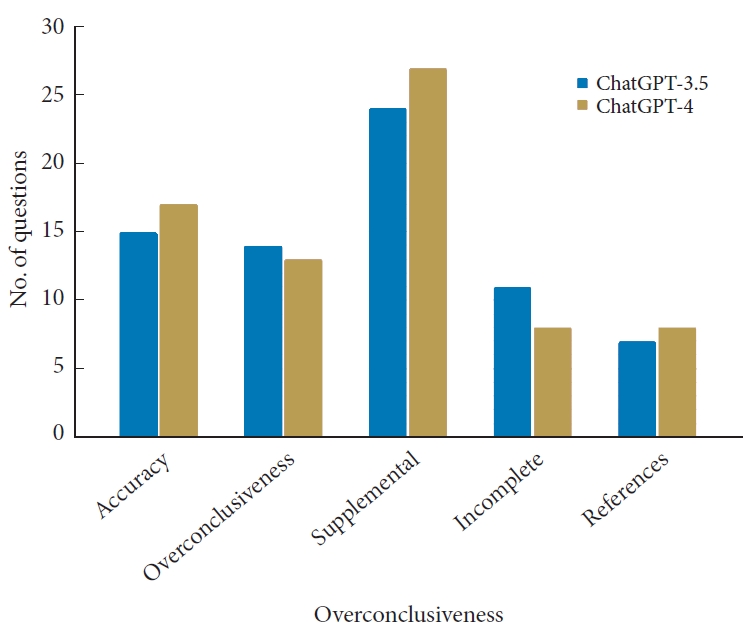
There were a total of 29 clinical scenarios that were included in the 2012 NASS guidelines relating to lumbar disc herniation with radiculopathy. ChatGPT-3.5 was accurate in 15 of its responses (52%) in which no contradictions were made to the NASS guidelines. However, ChatGPT-3.5 was overinclusive in 14 of its responses (48%) in which it provided a recommendation when the NASS guidelines did not provide one. In 24 of its responses (83%), ChatGPT-3.5 offered supplemental information, often explaining the procedures involved in various medical interventions or detailing how diagnostic tests are conducted. There were 11 responses (38%) in which ChatGPT-3.5 provided an incomplete response by failing to provide key information that was included in the NASS guidelines. Among the ChatGPT-4 responses 17 (59%) were accurate, 13 (45%) were overconclusive, 27 (93%) were supplemental, and 8 (28%) were incomplete (Table 1, Fig. 3). The differences in accuracy (52% vs. 59%, p = 0.792), overconclusiveness (48% vs. 45%, p = 1.000), supplemental information (83% vs. 93%, p = 0.650), and completeness (38% vs. 28%, p = 0.313) between ChatGPT-3.5 and ChatGPT-4 were not statistically significant. A detailed overview of the ChatGPT responses, are provided in Supplementary Table 1.
DISCUSSION
Given that the NASS guidelines for lumbar disc herniation with radiculopathy have not been updated since 2012, we anticipate that there may be gaps in the knowledge that were not provided in the text. Specifically, our group investigated some of the questions for which NASS was unable to give recommendations. It was of interest to analyze whether ChatGPT was able to provide more up-to-date information for clinical and patient use.
While no guidelines were published on NASS relating to differences in complication and outcomes between treatment sites, ChatGPT did give recommendations. Among ChatGPT’s recommendation, it describes that patients might be at lower risk for infection if surgical treatment for lumbar disc herniation with radiculopathy is treated in ambulatory surgical centers (ASC’s) as opposed to hospitals. ASC’s have indeed reported lower infection rates compared to hospitals after orthopedic surgery. One study found that the rate of infection in ASC’s following orthopedic surgery was 0.33% [6], while another study from 2021 found that inpatient infection rates following orthopedic surgery at a tertiary hospital was 0.3% for total hip, knee, and shoulder arthroplasty [7]. Interestingly, the same study reported that surgical site infection rates were even lower (0.2%) when the procedures were performed at specialty orthopedic hospitals [7]. This supports ChatGPT’s recommendation that there is a difference in complications depending on the surgical site where the procedure is performed.
Another study published in 2013, found that deep infection rates for multispecialty ASCs was 0.81% compared to 0.31% in single specialty ASC’s following orthopedic surgery [8]. While the recommendation that ChatGPT gave matched well among orthopedic surgeries in general, our group could not find any sufficient evidence that this is true for lumbar disc herniation with radiculopathy specifically. We hypothesize that ChatGPT generated a recommendation by extrapolating from general infection trends in orthopedic surgery across surgical sites. It is imperative to acknowledge that the incidence of surgical site infections, among other complications and outcomes, can vary considerably depending on the particular type of surgical procedure and the unique circumstances of individual patients. The aforementioned criticality has been duly recognized by ChatGPT.
The NASS guidelines did not provide any information relating to what it considered to be “value of treatment.” When ChatGPT was asked this question, it assumed that that the reader was asking about surgical techniques that are used to treat lumbar disc herniation with radiculopathy such as, microdiscectomy, endoscopic discectomy, and open discectomy. Its response stated that microscopic discectomy and endoscopic discectomy are associated with better outcomes and fewer complications compared to open discectomy. A randomized control study published in 2019 found that hospital stay, bone loss, estimated blood loss, and postoperative complications were all lower in microdiscectomy compared to open discectomy for patients with high level lumbar disc prolapse [9]. Although this is in line with ChatGPT’s response, the generalizability of this study is limited due to its small sample size.
A meta-analysis from 2022 analyzing pooled randomized control trials found that overall complication rates for full endoscopic lumbar discectomy (FELD) was 5.5% while complications for open discectomy/microdiscectomy was 10.4% [10]. This suggests that patients that received FELD procedures have a lower risk ration for overall complications (risk ratio [RR], 0.55; 95% confidence interval [CI], 0.31–0.98) [10]. While this is also in line with ChatGPT’s response, there was no significant difference regarding overall complications between the 2 cohorts. Interestingly, there was a difference in heterogeneous complication results suggesting that patients who receive FELD procedures to treat lumbar disc herniation with radiculopathy are at greater risk for dysesthesia (RR, 3.70; 95% CI, 1.54–8.89), residual fragment (RR, 5.29; 95% CI, 2.67–10.45), and revision surgeries (RR, 1.53; 95% CI, 1.12–2.08) [10]. Overall, the literature regarding complications and outcomes between surgical procedures is complex and future studies need to be performed before definitive statements can be made.
The NASS 2012 guidelines for lumbar disc herniation with radiculopathy give no recommendation or have abstained from commenting on the impact of the site-of-service chosen for surgical management on the value of treatment. ChatGPT, however, posits the notion that the chosen site-of-service can affect the value of treatment and defines the latter as “clinical outcomes” and “cost-effectiveness.” Despite the lack of evidence that NASS used to justify not commenting on the topic, ChatGPT suggested that hospitals tend to lead to higher costs compared to outpatient settings for the surgical management of this condition. A 2021 study concluded that outpatient lumbar discectomy (a type of surgical management for lumbar herniation) has a higher cost-effectiveness compared to its inpatient counterpart [11]. While this study may support ChatGPT’s conclusions regarding cost-effectiveness, this study is not generalizable due to its low sample size (N=40). Other studies have found that procedures like lumbar microdiscectomy can have reduced costs in the ambulatory setting compared to the hospital associated outpatient centers in patient populations insured with both Medicare and commercial insurances [12]. This evidence may suggest benefits in terms of cost-effectiveness for the surgical management of this spinal condition which is in line with ChatGPT’s response. However, these findings may not be generalizable and the patient population for which these findings may be true is a very specific one. The study found that relatively healthier populations would benefit more from outpatient surgery [13].
It should be emphasized that ChatGPT-3.5 is primarily a language model trained on a broad spectrum of general knowledge rather than specialized medical information [14,15], which might account for some of the observed variances when compared to NASS guidelines. However, given ChatGPT’s ease of access and increasing usage, it was crucial to evaluate its precision in delivering medically accurate information to ensure that patients are receiving reliable data. The latest version of ChatGPT-4, which benefits from training on a more extensive dataset updated as of 2023, has shown potential for improved performance in specialized areas including medical queries. This was evident in a recent comparative study between ChatGPT-3.5 and ChatGPT-4, specifically focusing on their outputs related to thromboembolic prophylaxis in spinal surgery [5]. In our study, however, there were no statistically significant differences between the responses provided by ChatGPT-3.5 and ChatGPT-4 which brings into question ChatGPT-4’s ability to perform better at domain specific information. Given this discrepancy, it’s crucial to recognize that ChatGPT is an evolving platform and as such, each new version should undergo ongoing validation to analyze its accuracy and reliability so as to ensure that patients are receiving accurate information.
The evolution from ChatGPT-3.5 to GPT-4 represents a significant milestone in the development of advanced language models by OpenAI. ChatGPT-3.5, released in early 2022, was an iteration based on the GPT-3 architecture and boasted around 6 billion parameters. This version was trained on diverse internet text up to 2021, enabling it to generate more contextually relevant and nuanced responses in conversational AI applications. While the exact number of parameters for GPT-4 was not publicly disclosed, it significantly exceeded the 175 billion, and was trained on a dataset inclusive of text and other data types up to the year 2022, enhancing its understanding and generation capabilities across a wider range of contexts and languages [16]. Additionally, OpenAI unveiled ChatGPT-4 Turbo on November 6, 2023, featuring a dataset current as of April 2023. This latest iteration introduces the capability to develop tailored models. With this enhancement, it’s possible to input extensive volumes of specialized data for targeted training, leading to more refined and precise outputs [17]. This advancement holds particular significance in medical applications. By feeding the model the latest medical data, specialized in certain areas of healthcare, it’s feasible to create a model that provides more accurate and up-to-date medical information.
Before the launch of ChatGPT Turbo-4, various teams had initiated the development of LLMs specifically tailored for the healthcare sector. A prominent example is Med-LLama, introduced in February 2023. This model builds upon the large language model meta-AI (LLaMA) framework, incorporating over 100,000 anonymized conversations between patients and doctors from an online medical consultation service. Med-LLaMA also integrates current information from online resources, along with various offline medical databases. This integration significantly enhances the model’s medical expertise and the precision of its advice [18]. Released in 2023, PMC-LLaMA is another significant contribution to the field of medical-specific domain LLMs. As an open-source model, it has undergone extensive refinement, having been fine-tuned with an extensive dataset of 4.8 million biomedical academic papers. This enhancement ensures that both patients and physicians can easily access precise medical knowledge, streamlining the information flow in healthcare settings [19]. It is important to note that literature is lacking on the specific utilization of Med-LLaMA and PMC-LLaMA, highlighting the importance of conduction analyses of these platforms to ensure their safety in the medical setting.
In the medical field, ChatGPT and other LLMs are being explored for various applications. A systematic review conducted following investigated ChatGPT’s utility in healthcare education, research, and practice. This review, which included 60 records, identified several benefits of ChatGPT: improved scientific writing, research equity, efficiency in analyzing datasets, utility in drug discovery, streamlining healthcare workflows, cost-saving, enhancing personalized medicine, and improving health literacy. It also found ChatGPT useful in healthcare education for promoting personalized learning and critical thinking. However, 96.7% of the records cited concerns, including ethical and legal issues, risk of bias, plagiarism, inaccurate content, and cybersecurity risks [20]. The review emphasized the need for cautious adoption of ChatGPT in healthcare, highlighting its potential to induce paradigm shifts in the field but also the necessity of addressing its limitations. In another recent study evaluating the diagnostic capabilities of ChatGPT-4, in neuroradiology, 100 cases from the American Journal of Neuroradiology were analyzed. ChatGPT’s diagnoses, based on patients’ medical histories and imaging findings, were compared with published ground truths, achieving an overall accuracy rate of 50%. These findings highlight the potential and limitations of ChatGPT in neuroradiological applications, further emphasizing its varied accuracy depending on specific medical conditions [21]. A recent literature review investigating the use of AI and machine learning in spine surgery, encompassing 46 studies, discovered that AI models achieved an accuracy rate of 74.9%. These models were particularly effective in patient selection, estimating costs, and predicting the length of hospital stays. Additionally, they demonstrated great performance in forecasting functional outcomes and the likelihood of postoperative mortality [22]. This underscores the importance of healthcare personnel to familiarize themselves with AI as a tool to potentially improve patient outcomes.
A significant difficulty in employing ChatGPT and comparable LLMs is their inclination to provide definitive answers to questions, even when a lack of agreement would be more fitting. This phenomenon, called artificial hallucination, happens when these models create plausible yet unsupported statements that are not backed by their training data [23]. ChatGPT-4 was previously found to avoid this issue of fabricated reference production [5], however, in our study we found that ChatGPT-4 still backed up some of its claims by fabricating studies. In response to queries about references, ChatGPT-4 clarified that it lacked the capability to cite specific references and instead generated responses based on the information it was trained on. Nevertheless, there were instances where ChatGPT-4 did indeed mention valid studies, which were subsequently verified by reviewers. Despite an improved likelihood of providing accurate references, ChatGPT-4 was not immune to occasional instances of generating erroneous information, reflecting the phenomenon of artificial hallucinations.
It is of considerable significance to highlight that the generation of medically pertinent queries is critical in acquiring informative clinical responses from ChatGPT. Although healthcare professionals and individuals with a healthcare-related background possess the necessary expertise to effectively generate such queries, nonexperts may encounter difficulties in doing so when attempting to obtain answers. Nonexperts may pose questions in an inappropriate or imprecise manner, resulting in inadequate responses from ChatGPT if they seek to substitute a medical consultation with a search query. As a result, it is imperative to exercise caution while utilizing ChatGPT and not to regard it as a substitute for medical consultations.
Our study presented some noteworthy limitations. Firstly, the NASS guidelines for lumbar disc herniation with radiculopathy have not been updated since 2012. It is probable that the guidelines have been updated since then with more literature being published on important criteria. This made it difficult to compare NASS guidelines with ChatGPT’s generated responses. Additionally, ChatGPT version 3.5 is only able to pull data until 2021, also making it outdated. However, we adjusted for this limitation by comparing ChatGPT’s responses to the most recent literature to see if it aligned well with what is being published. Although we thoroughly graded ChatGPT’s responses, there exists the potential for subjective bias when determining the grading of each response. To mitigate this, we had 2 independent reviewers’ grade ChatGPT’s responses while a third reviewer resolved any discrepancies. Despite these constraints, we offer an evaluation of the effectiveness of 2 distinct ChatGPT models in delivering accurate recommendations for lumbar disc herniation with radiculopathy.
CONCLUSION
ChatGPT shows promising potential for its use in clinical settings. It was often able to provide useful information that was not included in the 2012 NASS guidelines. However, employing ChatGPT as a tool for clinical management should be done so with caution so as to ensure the safety and quality of care given to patients. Although ChatGPT can be used as a tool for answering medically relevant questions, physicians and healthcare workers should continue to refer back to relevant literature, published guidelines, and their own expertise when making clinical decisions. Finally, lay individuals attempting to replace medical consultations with ChatGPT’s outputs should also take considerable caution given that its responses are based on the quality of the questions being asked. As AI continues to evolve, further research needs to be performed to investigate its use in clinical settings.